
In an ever-evolving insurance landscape where risk is getting more complicated and interconnected, risk analytics plays, and will continue to play, a critical role in creating and maintaining a competitive edge.
(Re)insurers and brokers continuously seek ways to enhance their analytical capabilities and use the latest science and analytical tools in their risk management workflows. The ability to store and access large data volumes of proprietary data assets plays a critical role in a firm's ability to develop this next generation of risk analytics.
Most firms employ traditional on-premises infrastructure, including large data warehouses, to store and process data and develop mission-critical analytics. The tool sets deployed for the analytical workflows typically include ETL (extract-transform-load) tools, such as SQL scripts and database stored procedures, and business intelligence (BI) reporting tools.
While data warehouse-based infrastructure and tools have served the industry for the best part of three decades, this new and evolving risk landscape demands more modern and scalable infrastructure. Firms that realize this shift and invest in upgrading their analytical capabilities and infrastructure can develop and sustain a competitive edge.
Shortfalls of traditional data lakes for risk management
A large volume of the data stored in these data warehouses is relational databases, with users connecting with these data warehouses through database connections and extracting data for their analytical needs. Business intelligence tools also connect with these warehouses to extract data and present insights to business users.
As data volumes grow and the analytical needs of a business evolve, working with these data warehouses starts to become a challenge. Users and IT administrators can find it extremely difficult to scale up the infrastructure to meet growing needs, as database queries that used to work on smaller datasets start running into issues when exposed to larger, and growing, datasets.
With the number of external industry-relevant data assets increasing in the market, the ability to quickly analyze data and derive business-relevant analytics becomes an important aspect of the business strategy. Firms that achieve scalability and agility can extract meaningful insights from these data assets and will stay ahead of the competition.
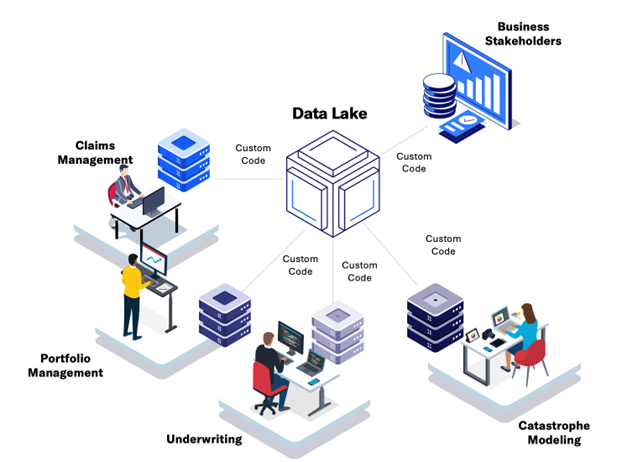
Introducing significant new data into a data warehouse is not a trivial task, as analytical teams must spin up large, long-running IT projects to acquire, store, and analyze such data assets. To achieve scalability and agility, firms have adopted ‘data lakes’ for their analytical needs, that are disconnected from their core risk modeling systems, and either built in-house or purchased from specialized technology vendors.
Data lakes have served as a valuable tool for many firms across financial services. They help simplify analytics by bringing large, distinct sources of data together under one storage architecture to help firms extract new insights from structured (relational databases), semi-structured (e.g. claims forms), and unstructured (e.g. aerial photos) data.
Data lakes decouple the storage and compute, providing scalability for users and/or administrators to increase or decrease the underlying resource allocation based on demand.
However, the deployment of a data lake disconnected from core catastrophe risk modeling systems often fails to meet the unique needs of risk management due to challenges with workflow integration. (Re)insurers and brokers often manage massive portfolios of risk that can be composed of billions of individual locations, and the corresponding size of the risk analysis on those locations is equally substantial.
For firms to take full advantage of their analytics across underwriting, portfolio management, and risk modeling, data needs to be exported from those applications or systems into an independent data lake, requiring the development of customized tools and processes to feed the data lake.
This can add complexity to their IT systems and environments, delay operationalizing the data lake into risk workflows, or, in the worst case, make it prohibitively expensive to maintain a data lake. Furthermore, firms can’t take full advantage of exploratory analytics within the external data lake unless all the required data has been exported to it.
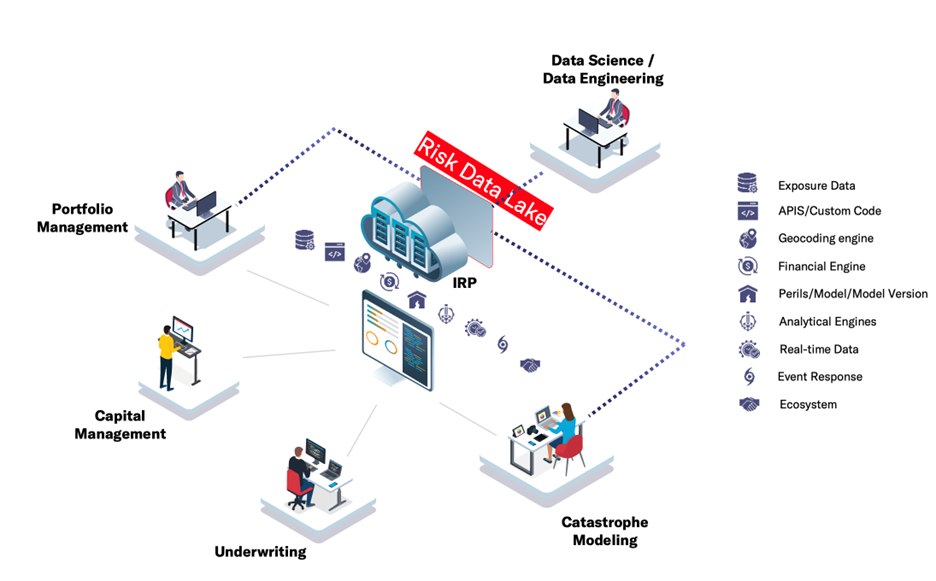
Introducing Moody’s Risk Data Lake
Moody’s Risk Data Lake is an innovative, next-generation cloud-based, programmable, and scalable analytical environment that is fully integrated with Moody’s Intelligent Risk Platform™ (IRP). The solution builds on the strengths of a traditional data lake architecture (scalability, performance, unified data storage across structured to unstructured data, and so on), but adds unique capabilities tailored for risk management.
The Risk Data Lake’s integration into the Intelligent Risk Platform provides instant access to the centralized data layer that underpins the Risk Modeler™, ExposureIQ™, TreatyIQ, and UnderwriteIQ applications. Centralizing these different analytics into a highly flexible storage layer dramatically eases the challenge of blending, combining, and extracting insights from different risk perspectives and data sources on the platform.
Firms utilizing Risk Modeler, ExposureIQ, TreatyIQ, and UnderwriteIQ do not have to move ANY of their data outside of the IRP to perform exploratory analyses. All their portfolio data, model analysis, accumulations, and other risk analytics are accessible with the same data access controls as their platform applications.
Critical to delivering unique insights and providing governed data to risk stakeholders is the data catalog. The data catalog allows users to facilitate search and maintenance and provides access to all exposure data as well as modeled losses, accumulation results, and other reference data in a highly intuitive, in-app interface.
The data is presented to the end-user in familiar risk schemas. In addition to the data from the platform, the Risk Data Lake and the data catalog allow users to import any other data assets that they want to incorporate into the analytics; data assets such as historical claims, additional policy details, or any external third-party data. This data can be in a structured or semi/unstructured format, then added to the catalog and can be easily joined with other data assets.
Flexible reporting to democratize access to advanced analytics
Moody’s Risk Data Lake provides various analytical tools for fast, flexible, and easy analytics development, empowering smarter data-driven decisions. One of these tools delivers flexible reporting capabilities to allow users to develop analytics across all their data within the risk data catalog, without needing to write a single line of code.
Using this flexible reporting functionality, the Risk Data Lake’s highly intuitive drag-and-drop interface allows technical as well as non-technical users to build risk analytics. Design pixel-perfect reports or dashboards by simply dragging-dropping data assets from the catalog, defining the dimensions, filters, and parameters, and the type of report. Users can preview the report and publish it for the broader team, including business leaders (see figure below).
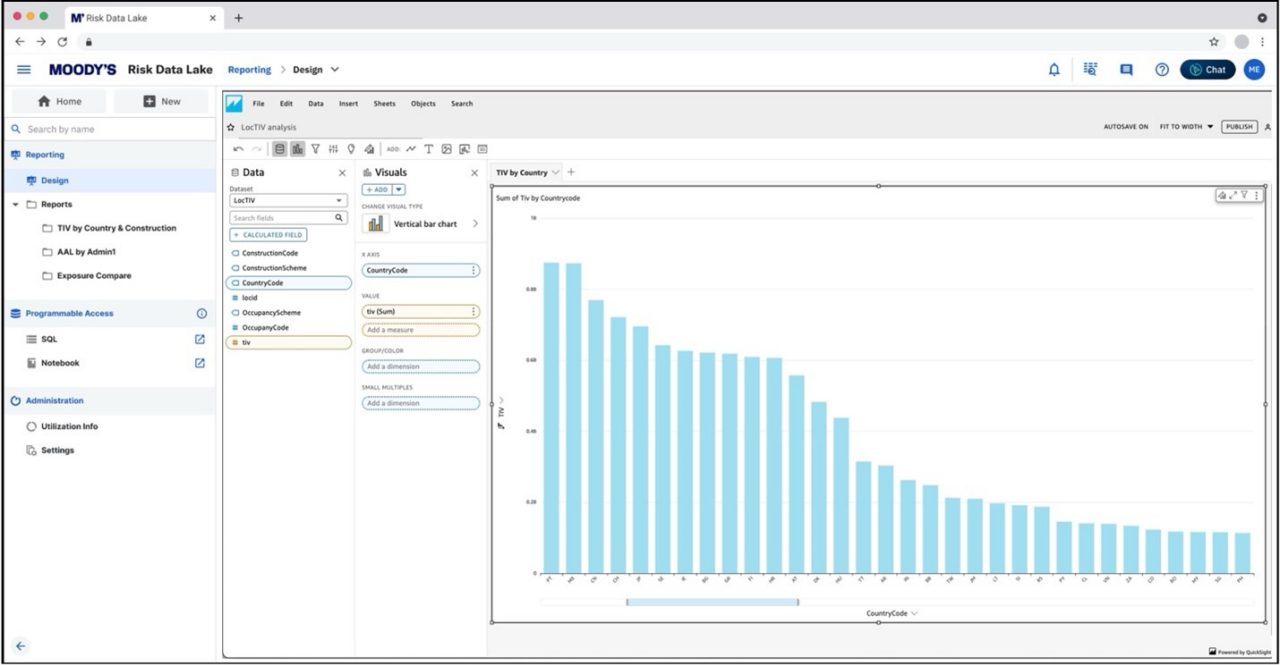
These reports and dashboards can be published in any IRP application. That means a business leader who uses Risk Modeler can get these advanced, flexible analytics reports delivered to them within the application, without any need to go into any other application.
The business leader can select the values for parameters and filters defined in the report, for example, region or peril, based on their areas of focus, and then render the report. Users can also view the underlying data and export it for further analysis or to feed into downstream workflows.
With access to all the data in one place and powerful and scalable infrastructure, this flexible reporting allows users to process large amounts of data and derive complex analytics without needing to create intermediate datasets purely to feed reports.
Programmable access to advanced data science capabilities
The Risk Data Lake also provides programmable access to all the data in the Risk Data Catalog.
More advanced users, who want to utilize tools such as SQL, Python, or R to analyze the data and develop advanced analytics, can utilize Risk Data Lake Notebooks and risk libraries. With its built-in integration with the IRP, the Risk Data Lake enables the processing of large amounts of data without data ever leaving the platform. Users can easily scale up/down the infrastructure based on the data volume and/or complexity of analytics, and can also schedule the execution of their notebooks and share both the code and results with other team members.
Advanced technical users, who want to utilize programming tools and notebooks for analysis, typically use their laptops to run the notebook and connect to data sources such as their corporate data warehouse or Data Bridge. Using notebooks to develop the code, when their code is executed, the data gets taxied between the source and the user’s laptop.
With the power of the Risk Data Lake, technical users have a far better and more powerful development environment to develop more advanced analytics, execute with appropriate compute resources, and provide timely analytical insights to the business leaders, without exporting data out of the platform.
Use cases
The Risk Data Lake enables a vast array of analytical use cases. Space and time won’t permit an exhaustive list here but here are a few use cases that clients have tried or expressed a strong desire to try:
- Exposure analytics – year-over-year comparison: Firms want to perform detailed analytics on their exposure data, and this includes performing a year-over-year comparison of their exposure composition. Questions such as “Are we writing more wood-frame construction compared to the recent past?” or “Profile of my portfolio compared to the industry.” Firms have developed SQL-based procedures to answer some of these questions but as data volumes grow and business leaders want to look at these trends going further back in history, these processes are struggling to execute successfully. They either take too long to complete or in many cases, just can’t run on larger data volumes.
- Modeled loss analytics – loss drivers and 'what-if' scenarios: Like exposure analytics, firms want to dive deeper into modeled losses and perform detailed analytics beyond what cat modeling applications provide. For example, identifying loss drivers by looking at various exposure characteristics and external data elements in relation to the modeled losses. Or running ‘what-if’ scenarios and comparing different versions of the modeled output. Using these insights then allows users to develop a custom view of risk and create a competitive edge in the market.
- Event response – timely insights: An extension of exposure and loss analytics is the event response use case where similar analytics is needed but there is a lot more time pressure given organization is dealing with an evolving cat event. As an event unfolds, there is a need to import an updated footprint and re-analyze the impact on the firm’s portfolio. Teams need to run multiple ‘what-if’ scenarios and provide timely insights to business leaders. Traditional infrastructure often fails to provide the required scale to perform these time-sensitive analytics. The Risk Data Lake would provide an ability to easily scale up the compute resources so that analyses can be completed faster.
The list above is nowhere near complete but provides a few examples of how new insights and better performance can be achieved in risk analytics workflows.
Whether your team has analysts looking for ways to develop analytics and provide critical insights to business leaders without needing to write a single line of code or highly technical data scientists who want to develop advanced analytics using SQL, Python, and R, or everything in between, the Risk Data Lake will provide infrastructure and tools to serve all your risk analytics needs.
Today, Moody’s Risk Data Lake is still under development but some of its functionality has been made available for clients to preview. By the end of the first half of 2025, more capabilities will be made available for preview with the targeted launch later in the year.
If you’d like to learn more about the Risk Data Lake and explore a preview of it to validate your use cases, please reach out to me.
LEARN MORE
Moody's insurance solutions
Our differentiated solutions bring together technology, data and analytics and insights, helping insurers, reinsurers, and brokers address their most complex challenges and make better decisions with confidence – therefore helping to close the insurance gap and drive performance.